This article will compare the floating point performance based on the following piece of Pascal code, between the Delphi 2007 and XE3 to see the difference at different configurations (e.g. DEBUG or RELEASE, INLINE ON or OFF, Single or Double).
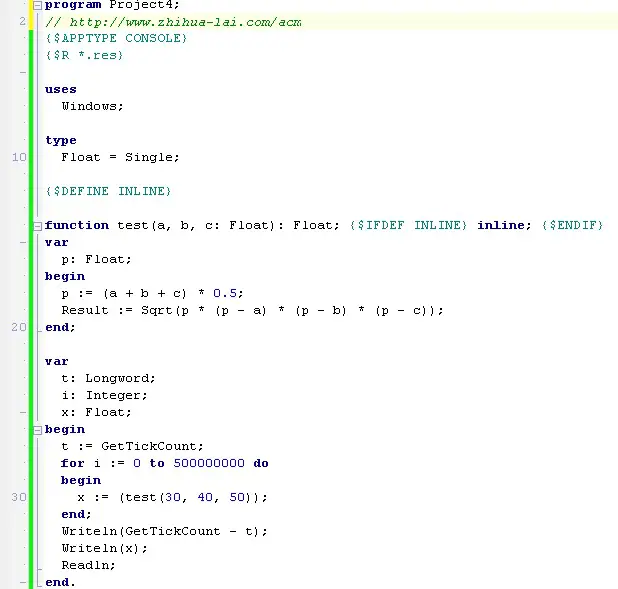
The above Delphi console program defines a function based on Heron’s Formula of the Triangle’s area. This function can be inlined by defining the compiler directive {$DEFINE INLINE}, which will put a inline keyword at the end of the function declaration. The Float type can be set to Single (4 – bytes) or Double (8 – bytes). Double takes twice size but offer a higher floating point precision and in general is slower than Single.
Later, we will replace the expression (a + b + c) * 0.5 with the division (a + b + c) / 2 and compare the performance differences. We use Windows API GetTickCount to time the interval between continuous 500000000 calls to the function test.
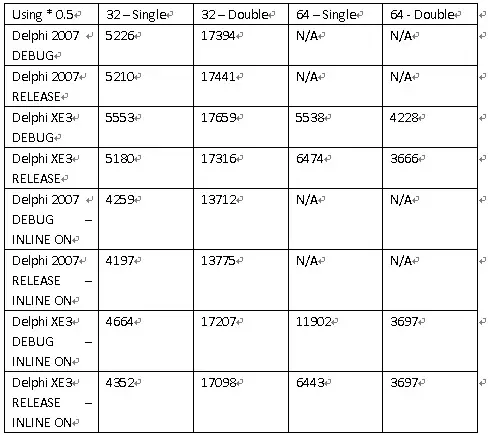
Below is the general performance matrix conducted based on the multiplication version (e.g. (a + b + c) * 0.5) The shorter number means a faster computation.
Below is the matrix for division version (e.g. (a + b + c) / 2).
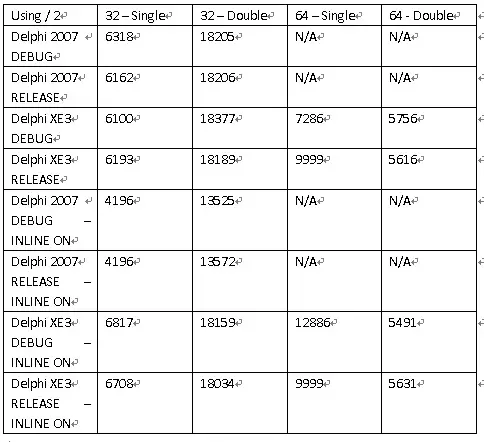
Comparison of above two tables, one thing obvious is that the Delphi does not impose optimization on floating point computation. It will substitute the slower division with the faster multiplication, in this case, / 2 or * 0.5
In most cases, the RELEASE version is faster than DEBUG version but may not be so obvious for Delphi compilers. There is only one exception in the experiment. The RELEASE version in Delphi XE3, the 64-bit executable is slower than its DEBUG version for 32-bit (Single) floating point manipulation.
In all cases, the inlined versions are much faster. Putting inline can be the simplest code optimization technique, that you should use when you distribute your software in RELEASE mode.
Delphi 2007 still produces quite optimized 32-bit FPU code on Single-size (32-bit) floating point computation. However, when it comes to double-size (64-bit) floating numbers, it tends to be very slow. On the other hand, Delphi XE3 produces a slower version of Single code but its Double code is much faster. This is due to the fact that on 64-bit executable, the FPU is no longer used, instead, xmm registers are used. The xmm registers are suitable for 64-bit Double precision operations but may be a bit slower for Single precision.
Let’s take a look at the following assembly code generated by Delphi compilers.
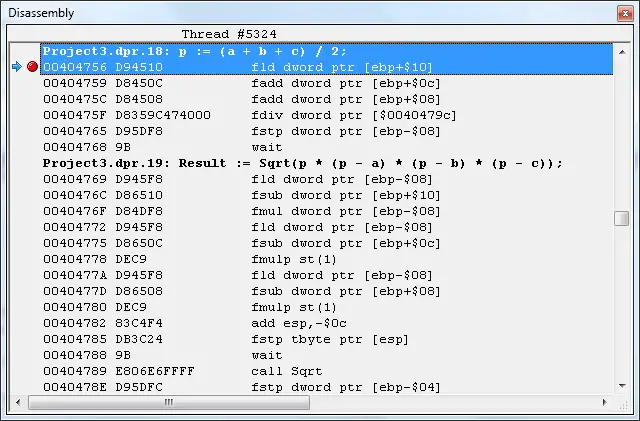
The below code is generated by Delphi 2007 compilers using expression p := (a + b + c) * 0.5 and we can see that: when size is Single, it uses addressing dword ptr; the fmul is used to times 0.5.
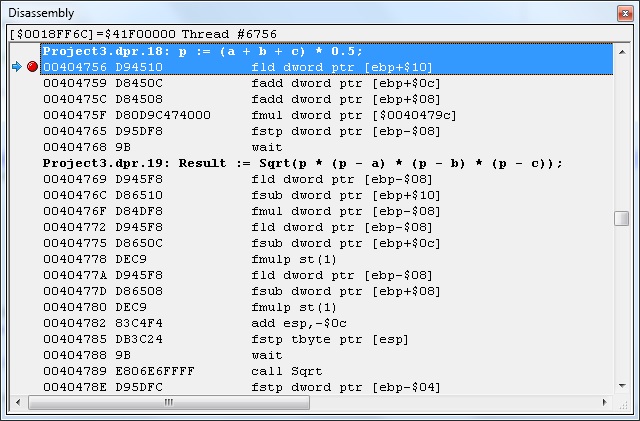
Since, there is no floating point optimization, you have to manually optimize you expressions, e.g. use mul instead of div. Otherwise, the code will be simply translated using fdiv.
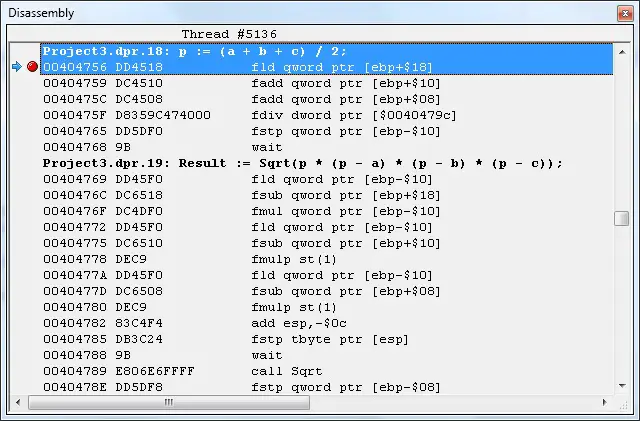
For Double Type, the qword ptr is used instead of dword ptr to address the values.
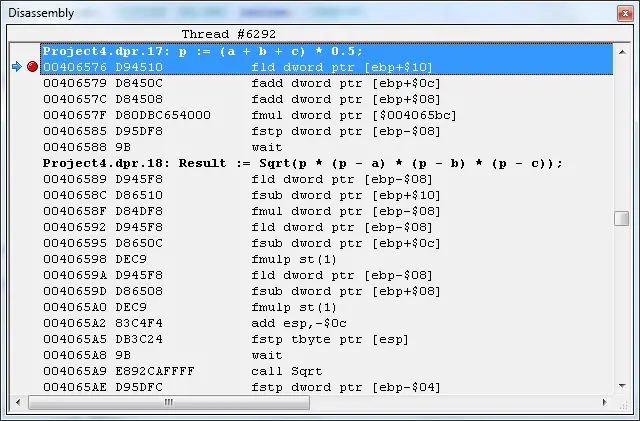
If using Delphi XE3, but still compiles into 32-bit executable. The FPU assembly code generation is almost the same. The instruction (9B, wait) will still be added, that could be taken out in most cases.
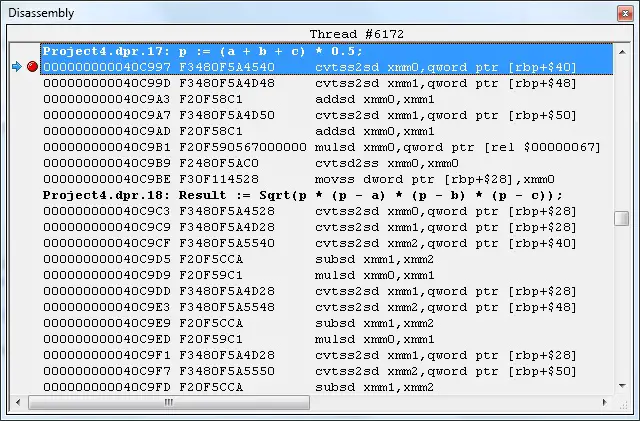
However, if compiled into 64-bit executable, the FPU will no longer be used. And below is the Single type version that uses xmm registers (SIMD, SSE). cvtss2sd converts to Double and cvtsd2ss converts back to Single, which is really slow everytime a Single type value is used. It is observed that qword is used because in 64-bit, the values are treated as Double by defaults.
And the Double version is much different because it does not need to convert everytime to double type and thus it is much faster for 64-bit floating numbers in 64-bit executable.
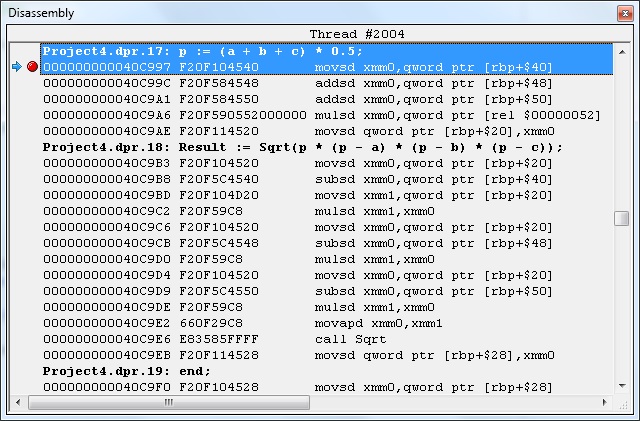
And similarly, if division is found in the expression, the div instruction will be used.
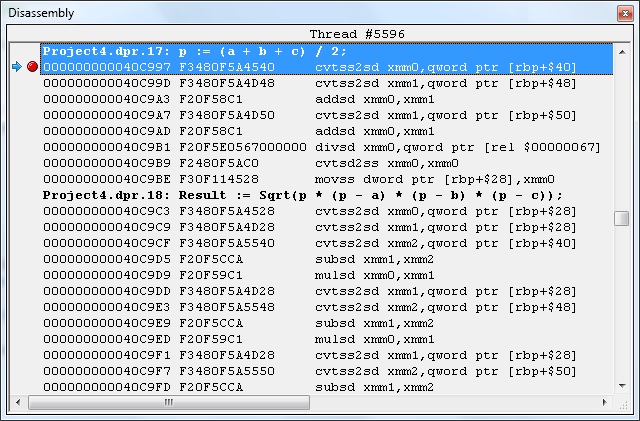
By using SSE instructions on xmm registers, the 64-bit executable perform much faster on 64-bit Double size floating numbers.
–EOF (The Ultimate Computing & Technology Blog) —
1308 wordsLast Post: Trick: Count the Number of API in COM
Next Post: Tower of Hanoi, Recursion