Boosting is an ensemble technique that attempts to create a strong classifier from a number of weak classifiers.
This is done by building a model from the training data, then creating a second model that attempts to correct the errors from the first model. Models are added until the training set is predicted perfectly or a maximum number of models are added.
AdaBoost was the first really successful boosting algorithm developed for binary classification. It is the best starting point for understanding boosting. Modern boosting methods build on AdaBoost, most notably stochastic gradient boosting machines.
AdaBoost is used with short decision trees. After the first tree is created, the performance of the tree on each training instance is used to weight how much attention the next tree that is created should pay attention to each training instance. Training data that is hard to predict is given more more weight, whereas easy to predict instances are given less weight.
Models are created sequentially one after the other, each updating the weights on the training instances that affect the learning performed by the next tree in the sequence.
After all the trees are built, predictions are made for new data, and the performance of each tree is weighted by how accurate it was on the training data.
Because so much attention is put on correcting mistakes by the algorithm it is important that you have clean data with outliers removed.
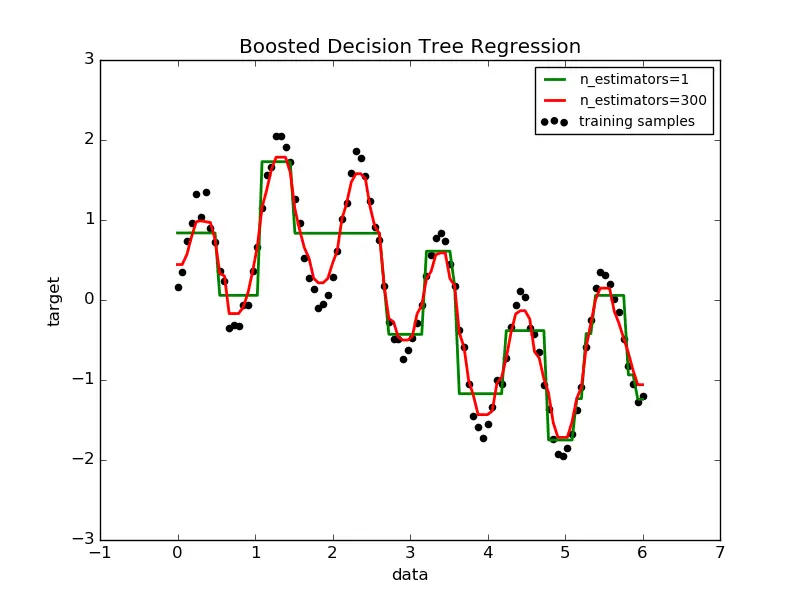
adaboost_regression
–EOF (The Ultimate Computing & Technology Blog) —
323 wordsLast Post: A Short Introduction: Bagging and Random Forest
Next Post: Gaming Adaptations for Different Platforms