The KNN algorithm is very simple and very effective.
The model representation for K-Nearest Neighbors Algorithm is the entire training dataset. Simple right?
Predictions are made for a new data point by searching through the entire training set for the K most similar instances (the neighbors) and summarizing the output variable for those K instances. For regression this might be the mean output variable, in classification this might be the mode (or most common) class value.
The trick is in how to determine similarity between the data instances. The simplest technique if your attributes are all of the same scale (all in inches for example) is to use the Euclidean distance, a number you can calculate directly based on the differences between each input variable.
KNN can require a lot of memory or space to store all of the data, but only performs a calculation (or learn) when a prediction is needed, just in time. You can also update and curate your training instances over time to keep predictions accurate.
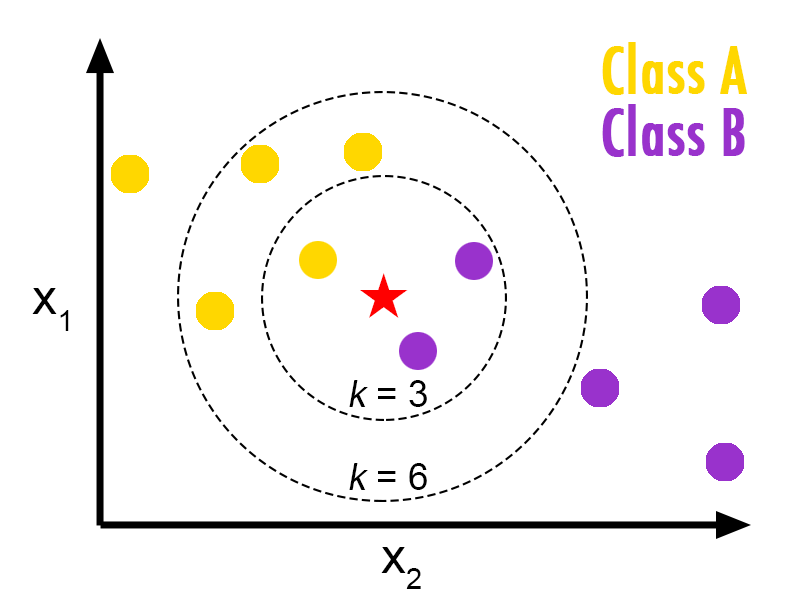
knn algorithm concept
The idea of distance or closeness can break down in very high dimensions (lots of input variables) which can negatively effect the performance of the algorithm on your problem. This is called the curse of dimensionality. It suggests you only use those input variables that are most relevant to predicting the output variable.
Other KNN Tutorials
- A Short Introduction to K-Nearest Neighbors Algorithm
- The K Nearest Neighbor Algorithm (Prediction) Demonstration by MySQL
- Teaching Kids Programming – Introduction to KNN Machine Learning Algorithm
–EOF (The Ultimate Computing & Technology Blog) —
376 wordsLast Post: A Short Introduction to Naive Bayes Algorithm
Next Post: A Short Introduction to Learning Vector Quantization