From this post, we know the non-deterministic approach to compute the approximation of math constant PI. The random algorithms e.g. such as xorshift need to be of high quality to obtain a good approximation.
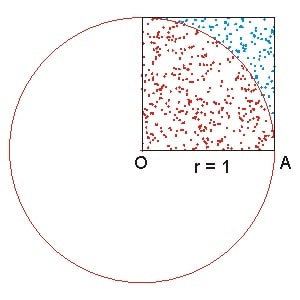
Monte-Carlo01
The idea is to generate as many as random sampling points as possible within a square, and count the number of samples that fall in the circle (compute the distance between this point to center (0, 0)) and the approximation of PI is equal to the ratio times 4.
So we can easily come up with the serial implementation in C++ or other programming language.
int monte_carlo_count_pi(int n) {
int c = 0;
for (int i = 0; i < n; ++ i) {
double x = (double)rand() / (RAND_MAX);
double y = (double)rand() / (RAND_MAX);
if (x * x + y * y <= 1.0)
{
c++;
}
}
return c;
}
Now, we can use Parallel.For to speed up the sampling using multithreads (concurrency).
int main() {
srand(time(NULL)); // seed
const int N1 = 1000;
const int N2 = 100000;
int n = 0;
int c = 0;
Concurrency::critical_section cs;
// it is better that N2 >> N1 for better performance
Concurrency::parallel_for(0, N1, [&](int i) {
int t = monte_carlo_count_pi(N2);
cs.lock(); // race condition
n += N2; // total sampling points
c += t; // points fall in the circle
cs.unlock();
});
cout < < "pi ~= " << setprecision(9) << (double)c / n * 4.0 << endl;
return 0;
}
The full source code is at github: parallel_monte_carlo_pi . cpp
The idea is to spread the total number of sampling points (each tiny job needs to count N2 points) among threads and count the number of points in the circle into variable c. Of course, to prevent race conditions, you would need to use critical_section to lock writing/updating these two variables.
If you run this C++ program, you will have around 90% of CPU usage. This is one tiny example to show you how to benefit from multicore processors.
If you run serial program on input N1*N2=100000K then you will have to wait for a bit while.
Feature Comments
I would have used atomic adds over the critical section. It's likely the CPUs will spend more time spin-locked than performing the random evaluation.
Monte Carlo Simulation Algorithms to compute the Pi based on Randomness:
- Teaching Kids Programming – Area and Circumferences of Circle and Monte Carlo Simulation Algorithm of PI
- Using Parallel For in Java to Compute PI using Monte Carlo Algorithm
- Monte Carlo solution for Mathematics × Programming Competition #7
- R Programming Tutorial – How to Compute PI using Monte Carlo in R?
- C++ Coding Exercise – Parallel For – Monte Carlo PI Calculation
- Area of the Shadow? – The Monte Carlo Solution in VBScript
- VBScript Coding Exercise – Compute PI using Monte Carlo Random Method
- Computing Approximate Value of PI using Monte Carlo in Python
- How does the 8-bit BASIC perform on Famicom Clone – Subor SB2000 – FBasic – Compute PI approximation using Monte-Carlo method
- GoLang: Compute the Math Pi Value via Monte Carlo Simulation
- BASH Script to Compute the Math.PI constant via Monte Carlo Simulation
--EOF (The Ultimate Computing & Technology Blog) --
897 wordsLast Post: PHP Script to Execute MySQL statements in a text file
Next Post: How to Show Posts of Historical 'Today' in WordPress?
Delhi Chalo Bhailog!